揭秘抱抱脸OpenAI的秘密武器,网易参与复现

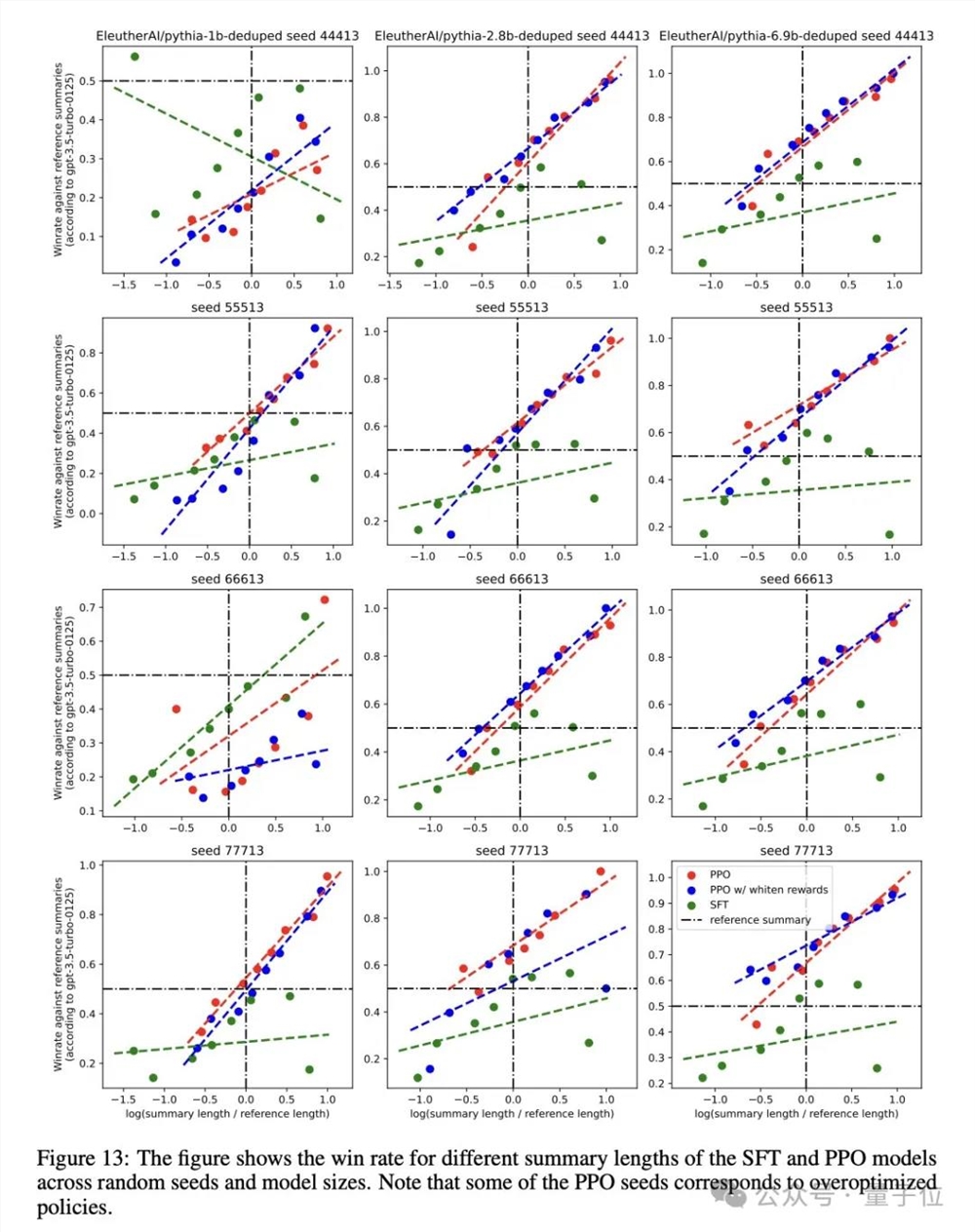
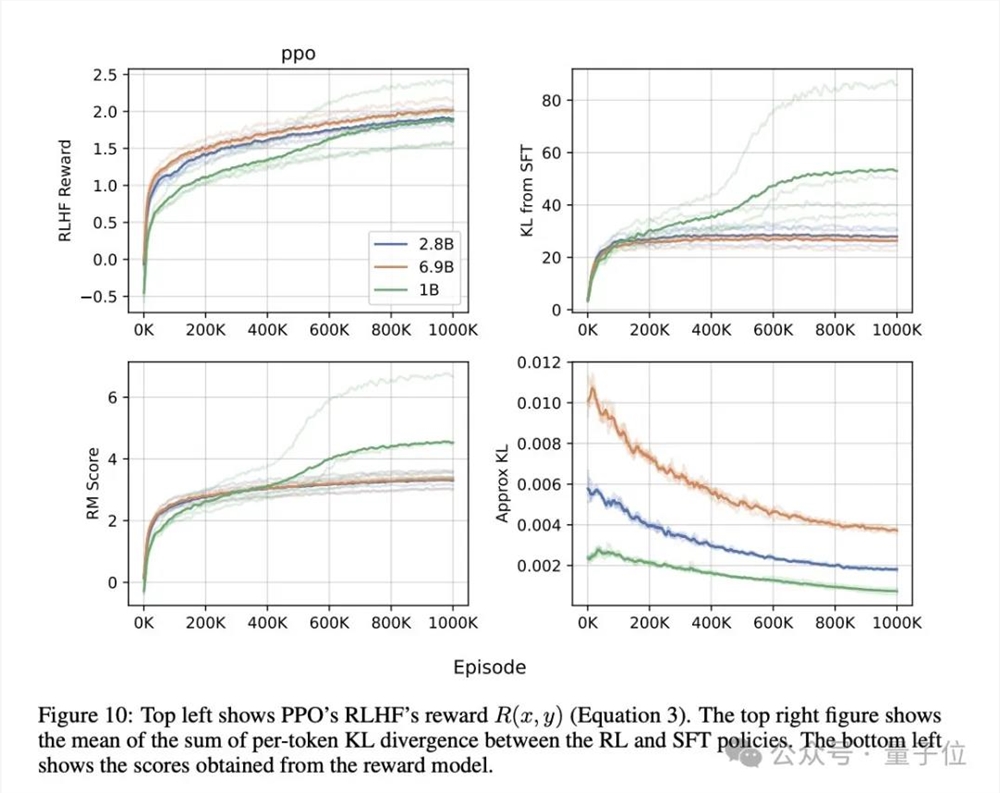
抱抱脸OpenAI的秘密武器RLHF一直是人们热议的话题,最近被开源了。Hugging Face、加拿大蒙特利尔Mila研究所、网易伏羲AI Lab的研究人员从零开始复现了OpenAI的RLHF pipeline,罗列了25个关键实施细节。他们成功展示了随着模型大小的增加,响应质量显著提升的scaling行为,其中2.8B、6.9B的Pythia模型在性能上超过了OpenAI发布的1.3B checkpoint。

除了已公开发布的训练好的模型checkpoint和代码外,还有一个初步的Pythia1.4B实验,显示这个1.4B模型非常接近OpenAI的1.3B性能。研究人员表示,他们的独特之处在于对SFT、RM和PPO使用了单一的学习率,使得再现工作更加简单。

Hugging Face最近上了一把新闻,抱抱脸现在是正式译名了。大语言模型的功能实质上就是在玩“词语接龙”,通过RLHF方法收集人类偏好,训练奖励模型(RM)来对这些偏好进行建模,并使用强化学习(RL)创建一个模型来输出人类喜欢的内容。OpenAI一直在探索RLHF,取得了显著进展。

在2020年的“Learning to summarize from human feedback”工作中,OpenAI将RLHF应用到摘要任务中,取得了优异的成绩。2022年的“Training language models to follow instructions with human feedback”工作中,RLHF再次被使用,为指令遵循任务而专门设计的InstructGPT诞生,成为GPT-3到ChatGPT的过渡论文。

RLHF作为秘密武器,开源界围绕着它做了不少工作,但要重现OpenAI的RLHF pipeline并不容易。主要原因在于RL和RLHF的微妙实现细节,评估模型表现的困难以及长时间的训练和迭代。因此,Hugging Face选择从OpenAI早期的RLHF工作中探寻OpenAI的RLHF的真面目,深入分析25个复现细节。
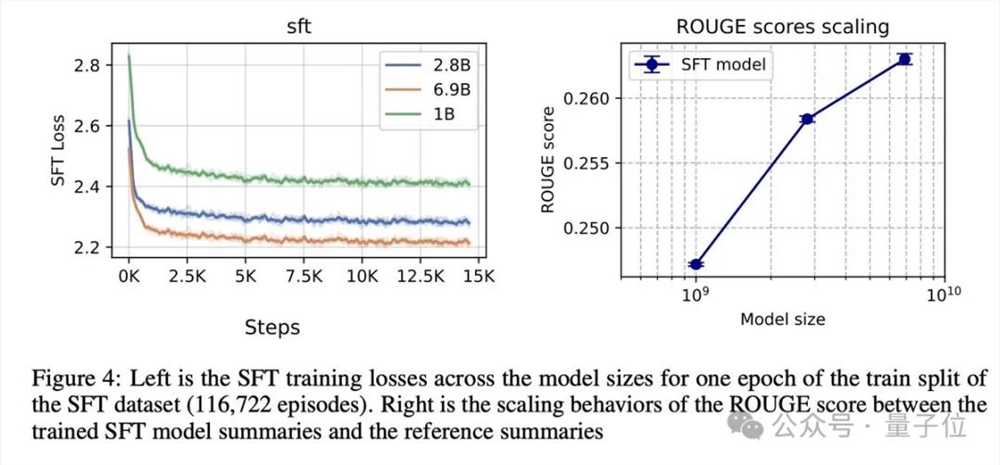
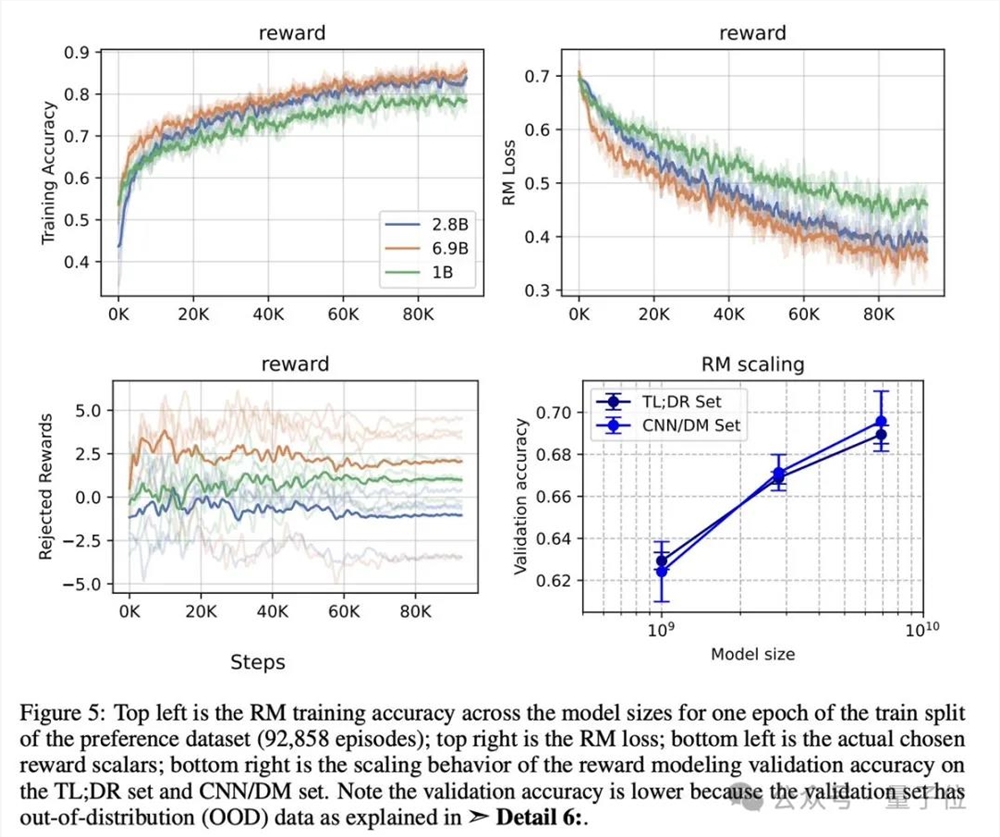
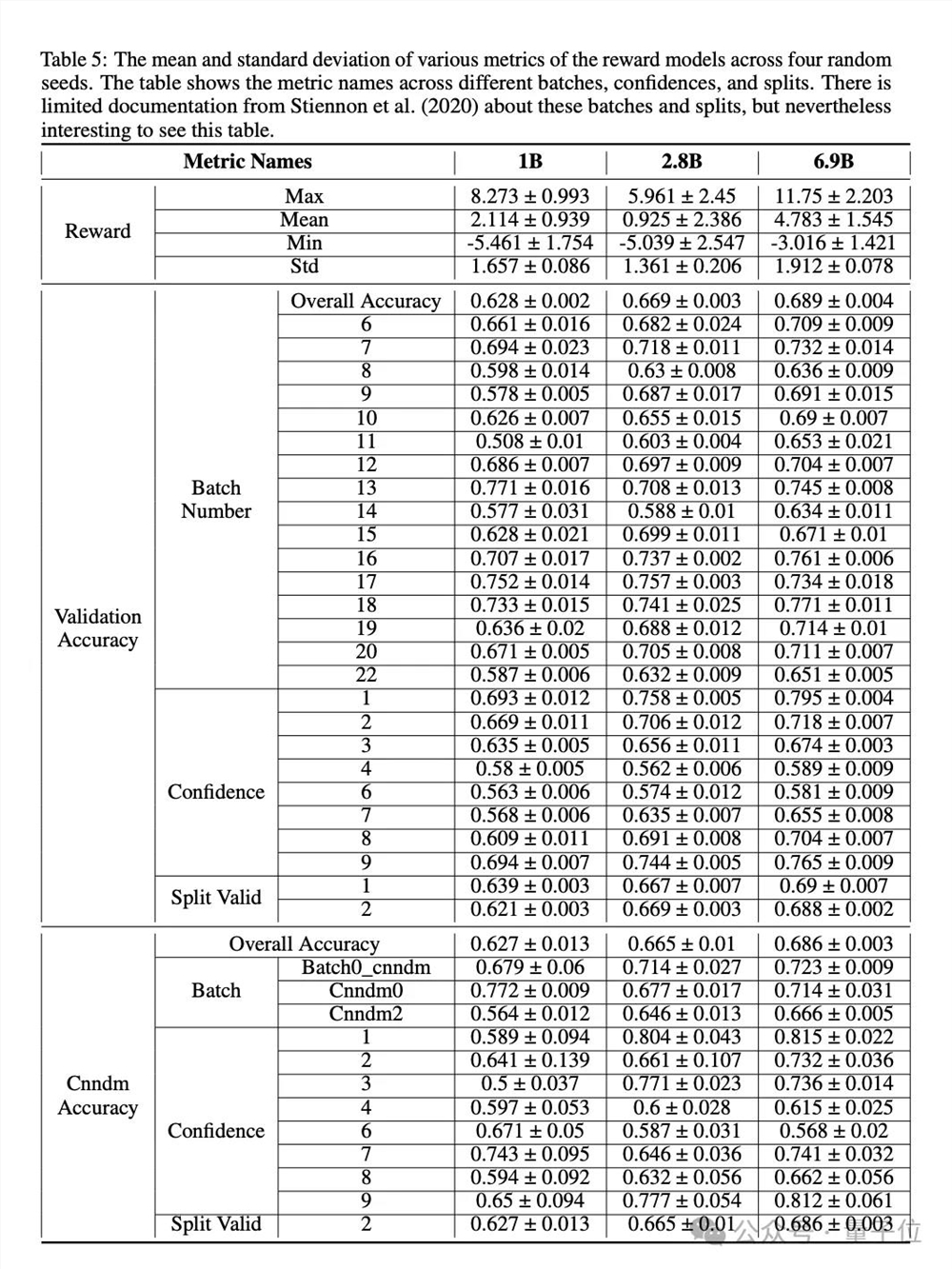
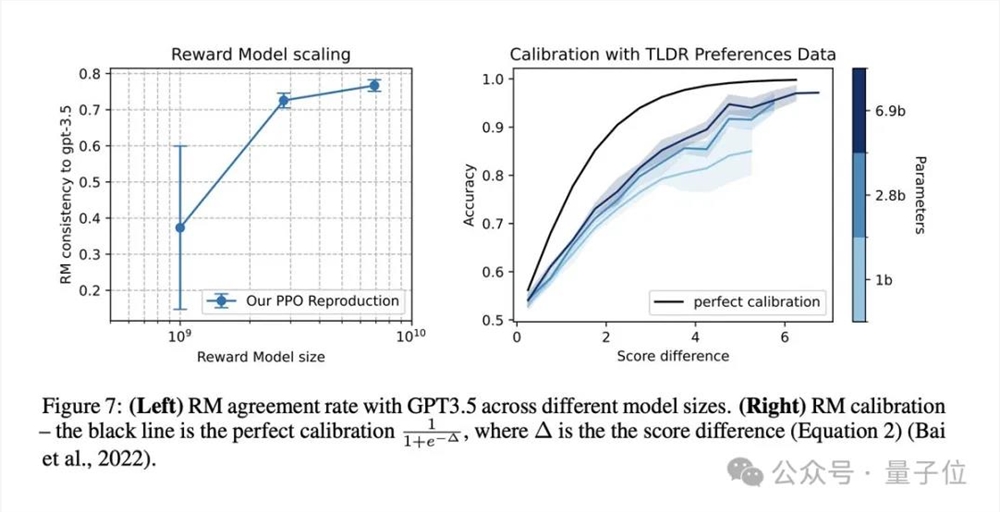
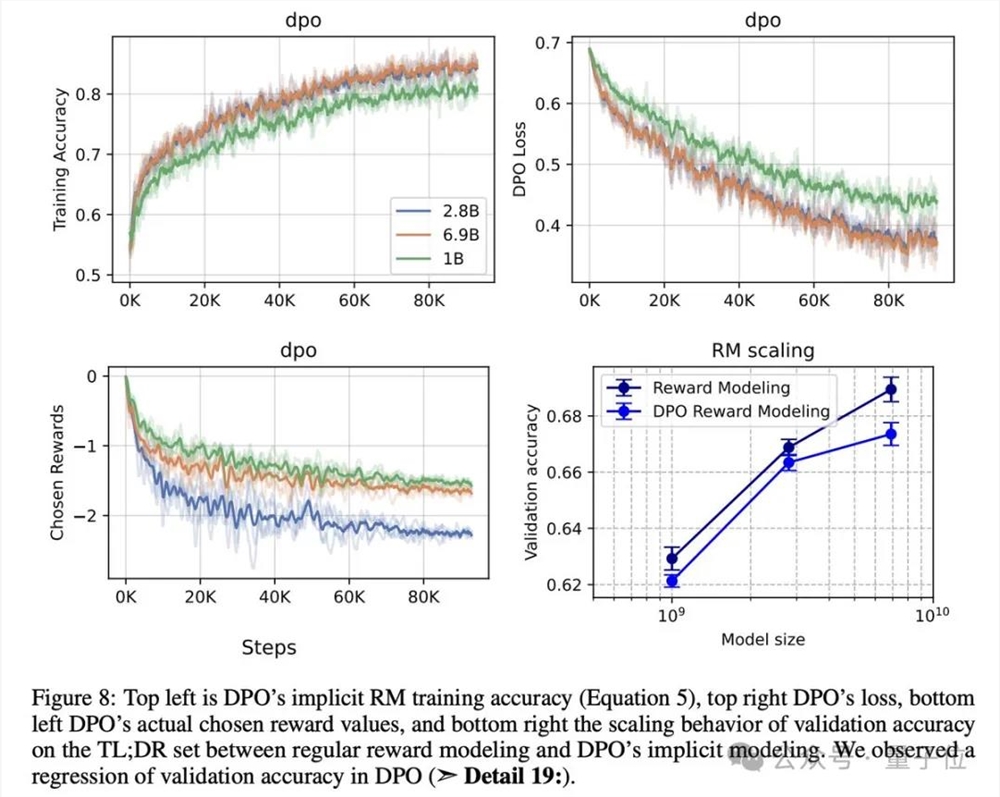
在复现过程中,研究人员从训练SFT策略、收集偏好对并训练RM、到针对RM训练RL策略,展开了深入的研究。他们详细描述了SFT和RM组件的训练设置、实施细节和结果,为了更好地理解模型的行为,还进行了可视化分析。
感兴趣的读者可以查看论文和GitHub链接,了解更多有趣的细节。抱抱脸OpenAI的秘密武器RLHF的开源,将为人工智能领域带来更多的探索和创新。